Prompt & Model Benchmark Lab
Benchmark LLMs on real tasks and get a data-backed pick — the right model for the right job, with the evidence behind it.
The Problem
Picking an LLM for a task is mostly vibes. Teams default to the biggest model for everything, or the cheapest, and never actually measure which one is right for this job. My own earlier tool, Prompt Test Lab, ran A/B tests — but its “scoring” was fake: keyword overlap and a hardcoded accuracy = 0.75. A benchmark you can’t trust is worse than none; it launders a guess as a number.
What I Built
The Benchmark Lab turns “which model should I use?” into a query with evidence behind it. One primitive — a Run = Cases × Candidates (model + prompt + params) — powers both model benchmarks and prompt A/B tests. Every output is graded for real: deterministic graders where ground truth exists, an LLM-as-judge (rubric, temperature 0) where it doesn’t, and every score carries a calibration confidence so you know how much to trust it. A POST /recommend endpoint takes a task plus constraints (cost ceiling, latency ceiling, quality floor) and returns a model, the reason, and its confidence.
The stack is Next.js 16 full-stack with a Bull/Redis worker for execution and grading, Prisma 7 on Postgres, multi-tenant from the schema up, with a fail-closed cost gate and OpenTelemetry gen_ai spans on every model and judge call. It runs against cloud providers (Groq) and on-device models via Ollama — keyless, zero marginal cost — so you can compare cloud vs local on the same tasks.
Why It Matters
Model choice is a per-task decision, not a global one. A subtle security audit and a bounded CRUD endpoint reward completely different models — and on bounded work, the expensive tier often buys nothing. Without measurement you can’t see that; you just overpay or underperform. This makes the trade-off legible: same tasks, same grading, real numbers, with the confidence attached.
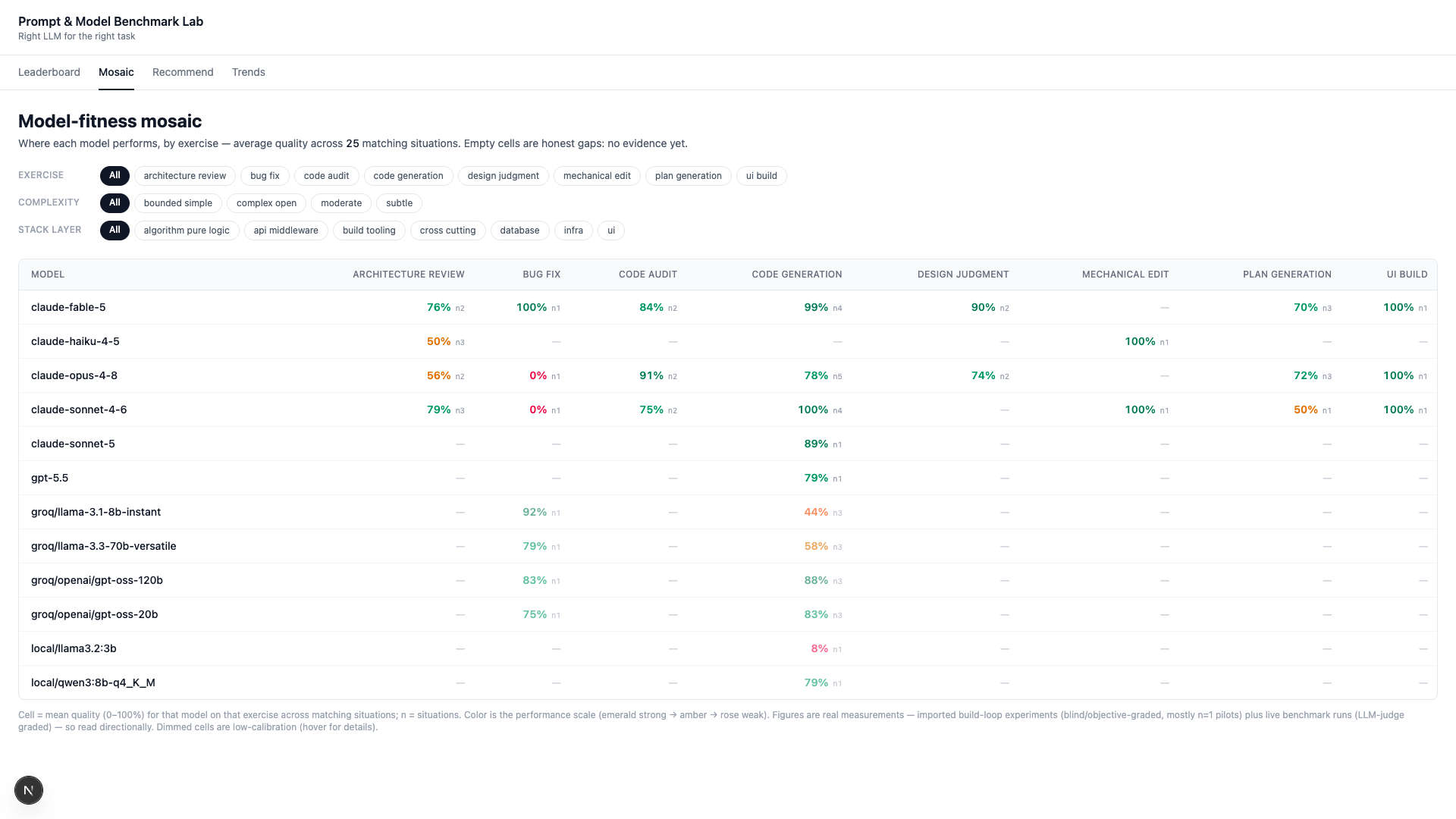
The Model-Fitness Mosaic
The signature view is a mosaic — every model scored by exercise (audit, planning, code-gen, bug-fix, UI), complexity, and stack layer (UI, middleware, database, infra). Filter to a situation and read who wins. Empty cells are honest gaps: “no evidence yet,” not a fabricated zero.
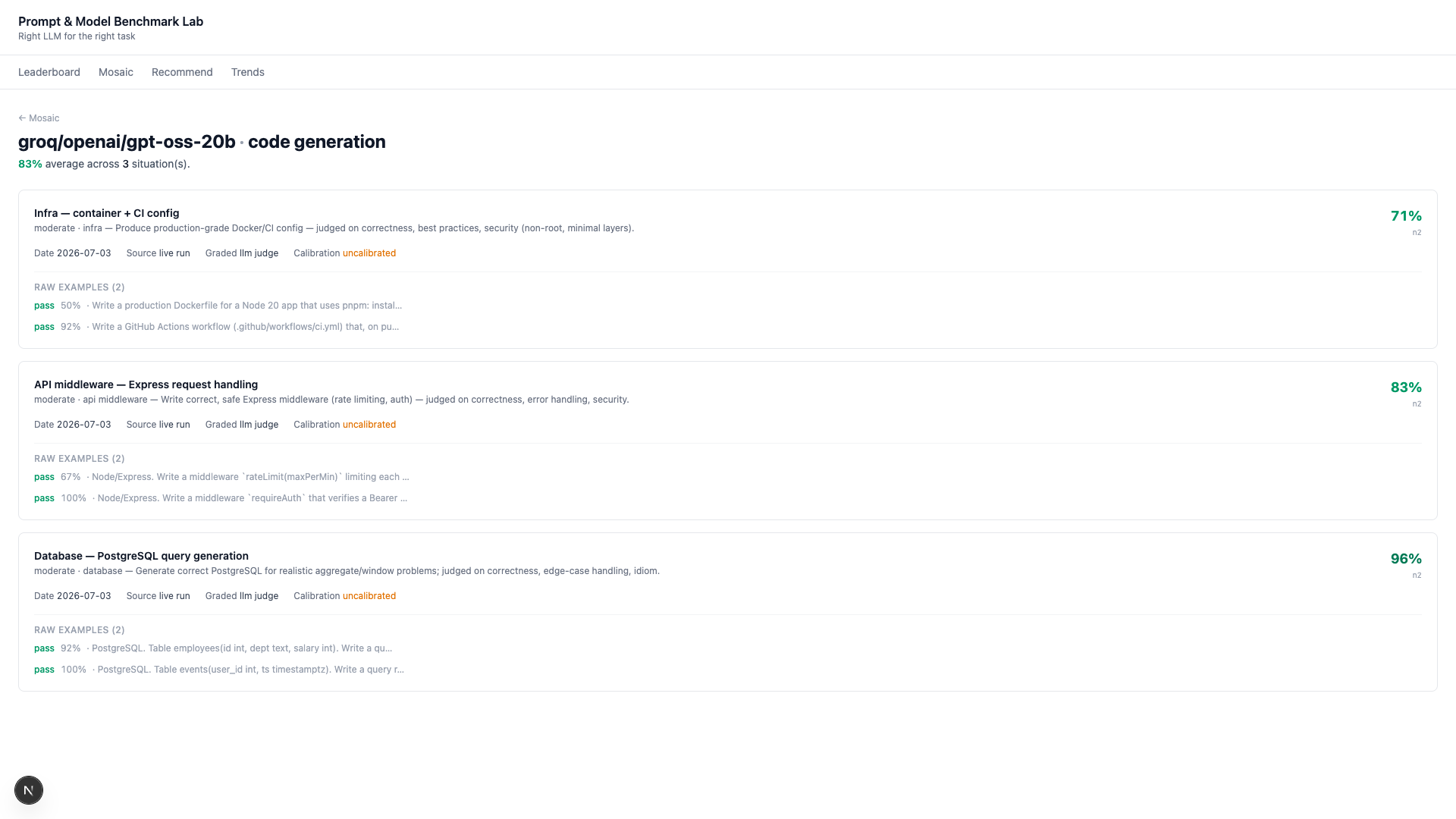
Evidence You Can Drill Into
Every score is clickable. Open a cell and you see each contributing run: the date, how it was graded, the calibration, and — for live runs — the raw prompt, the model’s actual output, and the judge’s verdict and rationale. A one-line Trust banner tells you straight whether the evidence is objective, mixed, or judge-only-and-directional. No number hides its provenance.
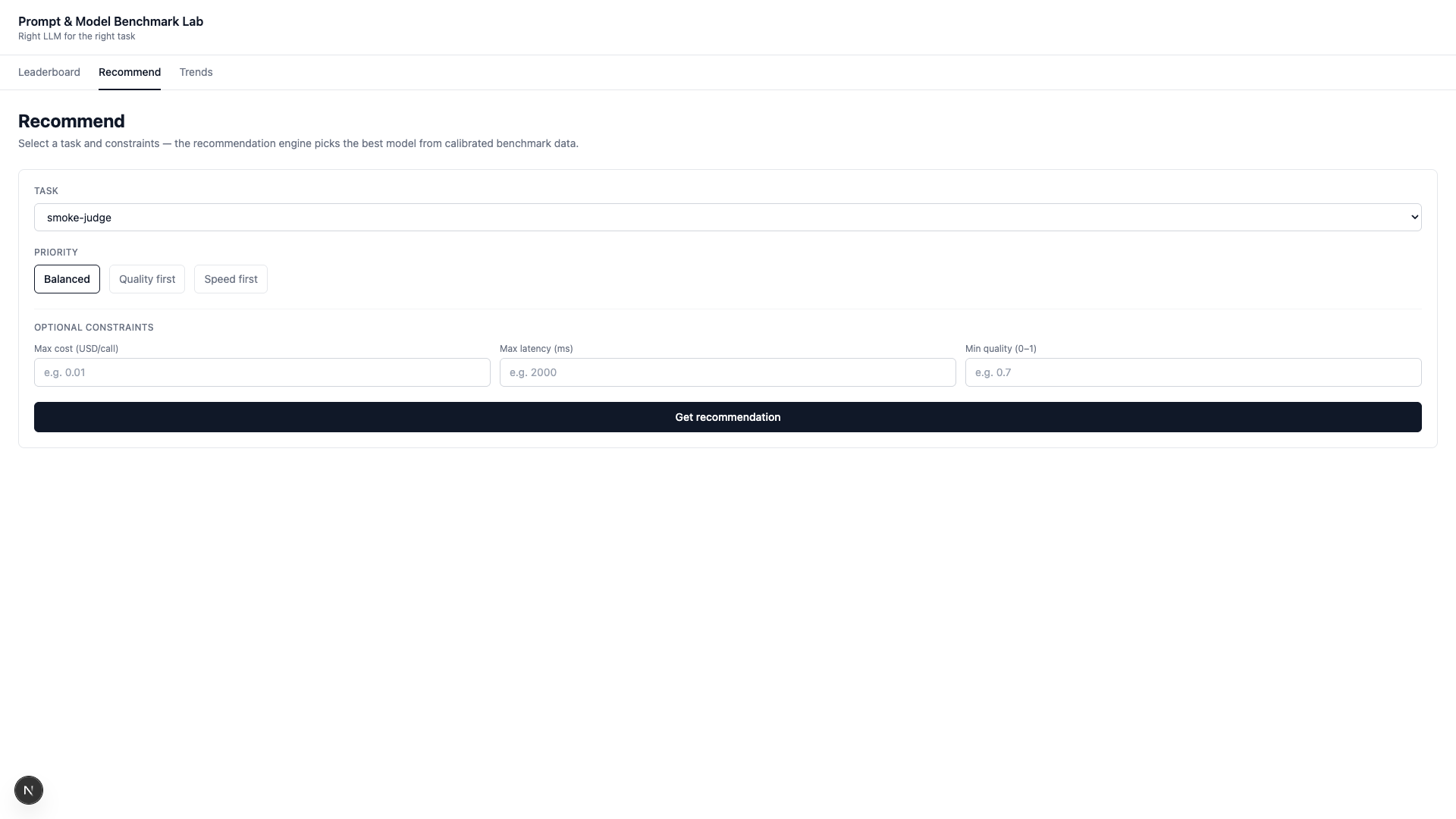
Recommendation, Not Just a Leaderboard
The leaderboard makes the evidence inspectable; the recommendation explorer turns it into an answer. Pick a task and priority (speed, quality, balanced), set optional constraints, and it returns the model with a cited reason — quality, cost, latency — plus its confidence and the alternatives it beat.
Two Kinds of Evidence, One Wall Between Them
The benchmark is prospective and calibrated. But real build sessions across my other projects generate their own model-fitness signal — which model shipped a chunk, whether it held. The lab ingests these as field observations, quarantined behind a hard wall: they show up as corroboration, but they can never blend into a calibrated score or move a recommendation’s confidence. Observational evidence stays labeled observational.
Technical Decisions
Grading is the crux, so it’s the part I was strictest about. The judge is gated by calibration and can never set its own composite — that’s computed in code from its per-dimension scores. When the judge model happens to be one of the candidates, the pipeline flags the cell self-graded and strips its confidence, because a model scoring its own work isn’t evidence. A subtle capture bug surfaced along the way — reasoning models (gpt-oss) return their answer in a separate field, and reading only the usual one silently recorded blanks — which turned into a durable lesson: always sanity-check output length against tokens spent before trusting a score.
The result is a benchmarking tool that’s honest about its own uncertainty — which, for a tool whose entire job is producing trustworthy numbers, is the only version worth building.